Projects
Research Projects
Data-Centric Computing
A wide range of application domains are emerging as computing platforms of all types become more ubiquitous in society. Many of these applications are data centric, and spend a significant fraction of their time on accessing and processing very large datasets. Examples of these applications include graph frameworks, precision medicine, computer vision, deep learning, and mobile device workloads. Unfortunately, the hardware platforms executing these applications remain compute centric, and are rooted in decades-old design principles for computer architectures. Running modern data-centric applications on compute-centric platforms results in high inefficiencies, with significant energy waste and program stalls. Data-centric platforms can eliminate these inefficiencies, but require the community to fundamentally rethink our approach to computer design.
Our work is designed to enable the development and widespread adoption of data-centric computers. This work spans the entire compute stack, starting from the device level up to software runtimes. We have developed an application-driven approach for identifying how and when to make use of data-centric computing, and have developed mechanisms that can provide essential and efficient support for traditional multithreaded programming. We are also exploring several application domains that can benefit from data-centric computing, and are performing hardware/software co-design to develop novel solutions for these domains.
Selected works:
Load Criticality
 Imagine what would happen if FedEx ignored the urgency of a package, and simply tried to ship as many packages as possible at a given time.
Their throughput would increase significantly, but time-sensitive packages would be delayed, creating issues for customers waiting on these shipments.
This is exactly how memory schedulers have been designed in the past -- bandwidth is improved through memory-level parallelism, with the incorrect thought that this improves performance.
Imagine what would happen if FedEx ignored the urgency of a package, and simply tried to ship as many packages as possible at a given time.
Their throughput would increase significantly, but time-sensitive packages would be delayed, creating issues for customers waiting on these shipments.
This is exactly how memory schedulers have been designed in the past -- bandwidth is improved through memory-level parallelism, with the incorrect thought that this improves performance.
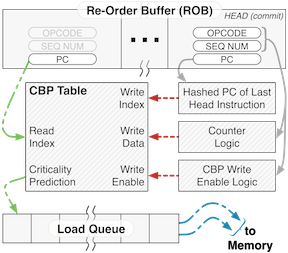
Our work finds which loads are important to a core, by having the core itself identify them, and prioritizes them in memory. We find that, even if this comes at the expense of memory throughput, the proper identification of the criticality of a load provides significant performance improvements. Surprisingly, this processor-assisted information is so helpful that even a tiny criticality prediction mechanism can be used to garner large gains.
With the memory controller on chip, bandwidth between the controller and the cores is no longer at a premium. Furthermore, growing DRAM frequencies will make it exceedingly difficult to continue adding logical complexity to the memory scheduling logic. With our processor-assisted approach, we can decouple the load analysis from the scheduler by piggybacking criticality information on the memory request, keeping the scheduler lean yet sophisticated. Using this improved scheduling approach, we can achieve mean speedups of 9.3% for parallel applications, all with less than 2 kB of total storage overheads for an 8 core, 4 memory channel system.
Improving Fusible Multicore Architectures
 Fusible multicore architectures, such as Core Fusion (İpek et al., ISCA '07), attack the inefficiencies of critical section execution on traditional chip multiprocessors (where most of the cores remain idle).
This is accomplished by combining several components of the cores together to dynamically create a single, highly-superscalar processor when a critical section is reached.
Fusible multicore architectures, such as Core Fusion (İpek et al., ISCA '07), attack the inefficiencies of critical section execution on traditional chip multiprocessors (where most of the cores remain idle).
This is accomplished by combining several components of the cores together to dynamically create a single, highly-superscalar processor when a critical section is reached.
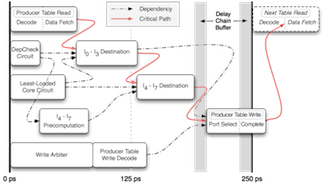
Our work addresses the prior deficiencies of Core Fusion, whose fused large core underperformed when compared to an area-equivalent, monolithic core. Two techniques (NOP compression and an improved instruction steering algorithm) allow us to recover this performance loss. Offline genetic programming was used on a training set to search for the best steering policy. In order to validate that the steering algorithm met our aggressive 4 GHz target frequency, we created a detailed circuit-level model in a 45 nm process. Through several logical optimizations and careful transistor sizing, we designed a circuit that, when scaled conservatively to smaller process technologies, met our timing requirements with adequate margins.
Memory Violation Detection
The C and C++ programming languages are notorious for providing unsafe access to memory objects. Bugs originating from illegal memory pointer usage are a major source of program error. Previous schemes to detect such violations have been software-based, and result in overheads that can slow programs down by an order of magnitude.
We developed compiler-assisted architectural mechanisms that can perform runtime detection of out-of-bounds references. With optimizations that reduce the detection latency and overhead, we provide full-coverage pointer detection with only a 5% average performance impact.
Selected Projects Completed at Cornell
Training Robots to Mimic Human Actions
Work by Koppula et al. (IJRR, '13) demonstrated how a Willow Garage PR2 robot could use RGB-D video from the Kinect sensor to observe and learn human activities and object affordances (relations between objects and other objects, as well as between objects and actions). We extended upon this work by using the learned trajectories and affordances to extract generalized motion paths for the robot to execute, in effect learning how to mimic the actions demonstrated by a human. Using inverse reinforcement learning, several combinations of features were used to extrapolate the trajectories for four observed activities.
Benchmark Acceleration Using Portable Subword SIMD
Data-parallel architectures have made a resurgence in computer architecture research. Recently, GCC 4.7 added support for portable vector operation implementations, the known as the GCC Vector Extensions. With a beta version of the compiler, we present a case study comparing the performance of an explicitly-vectorized version of streamcluster using the Vector Extensions against the automatic vectorization of the Intel C++ Compiler for a Core i7 family processor.
Ad-Hoc Networks for Systems-on-Chip
Systems-on-chip (SoCs) have primarily used simple on-chip networks for communications between different components, typically relying on buses or point-to-point networks. In contrast, Dally and Towles (DAC '01) argue that regular packet-switched networks provide better scalability and easier design. However, total rigidity is not conducive to the heterogeneity of SoCs, as each component can have vast differences in communication requirements. We designed an automated tool flow that selectively replaces low-throughput point-to-point SoC channels with ad hoc routers, delivering greater overall network bandwidth as needed.
Memory-Aware DVFS for CMP Systems
VSV (Li et al., MICRO '03) proposed to scale down processor voltage any time an L2 miss occurred. We extended VSV to work on a chip multiprocessor executing multiprogrammed workloads. As part of our work, we evaluated how VSV, along with our multicore extension, operated for various DVFS transition latencies. We found that memory-aware scaling only provides tangible ED2 improvements for very short latencies (12 ns), and even then does so at a significant performance cost.
Ultra Low Power 16-Bit Processor
A student team designed the ISA and microarchitecture for an ultra low power processor, for use in a low power GPS tracking device. The processor uses a modified version of the 16-bit MIPS ISA, with custom instructions for common GPS operations, and power optimizations such as dual-phase clocking. The chip was fabricated using a 130 nm process, with a target frequency of 50 MHz with 35 mW TDP. GNU binutils and GCC were ported to our ISA to provide a toolchain for high-level language compilation.
Learning Instruction Criticality
Instruction criticality has previously been expressed as a directed acyclic graph which can be found using reverse graph traversal, but this is difficult to identify at runtime, when only the forward flow is available (Fields et al., ISCA '01). We explored how several machine learning algorithms could be used to improve upon the token-based Fields criticality predictor, by training them on a number of dynamic instruction features. We found that decision trees offer the greatest prediction accuracy, achieving a 95% test set prediction accuracy.
Asynchronous Floating-Point Adder
Synchronous floating-point units often incur high latencies, as their circuit designs must account for worst-case timing for a number of corner cases that require significant additional computation yet rarely occur. Unlike synchronous circuits, asynchronous circuits can significantly reduce the latency of these common cases, by allowing them to complete earlier and notify their consumer immediately. Corner cases simply diverge in the datapath, thus extending the unit's calculation latency only when necessary. We designed the first pass of a single precision IEEE 754 asynchronous floating-point adder, and implemented much of this design at gate level.